Large language models keep solving tasks we thought required vision, like visual question answering, spatial reasoning, even robotic manipulation. This has led some to ask: do we even need pixels, or is language all you need?
The Platonic Representation Hypothesis says it doesn't matter. As neural networks scale, their representations converge toward the same one regardless of modality. If true, you might just use text, since it's a convenient source of data.
But there is a reason we visit art museums rather than just read descriptions of paintings in a catalogue. And when we looked closely at the experimental evidence for convergence in the Platonic Representation Hypothesis, we found that it came from a surprisingly limited setting. The evaluations were done on just 1,024 samples with bijective pairings. Under more realistic conditions, what looked like little alignment turns out to be shallow. Both models sometimes agree on broad categories but organize the finer details differently.
The core metric used by Huh et al. to measure cross-modal alignment is mutual k-nearest neighbors (mutual k-NN). Given paired image-text data, find the (k) nearest neighbors for each sample in both the vision and the language embedding space.
Use the slider below to grow the dataset size. As it gets denser, both models find closer neighbors, but they stop agreeing on which one:
The original experimental evidence for the Platonic Representation Hypothesis used a dataset of just 1,024 samples. We systematically scaled up to 15 million, and found that alignment degraded.
Why does this happen? In a sparse dataset, both modalities tend to retrieve the same neighbors, not necessarily because they agree, but because the pool is too small to reveal their differences. As the dataset gets denser, each modality can find neighbors that are closer in its own space, and the overlap vanishes.
Huh et al. themselves ask whether the obtained mutual kNN score is “indicative of strong alignment with the remaining gap being ‘noise’ or does it signify poor alignment with major differences left to explain?” When scaling from 1,024 to 15 million samples, the alignment score drops from 13.5% to just 0.81%, leaving very little room for a convergence narrative.
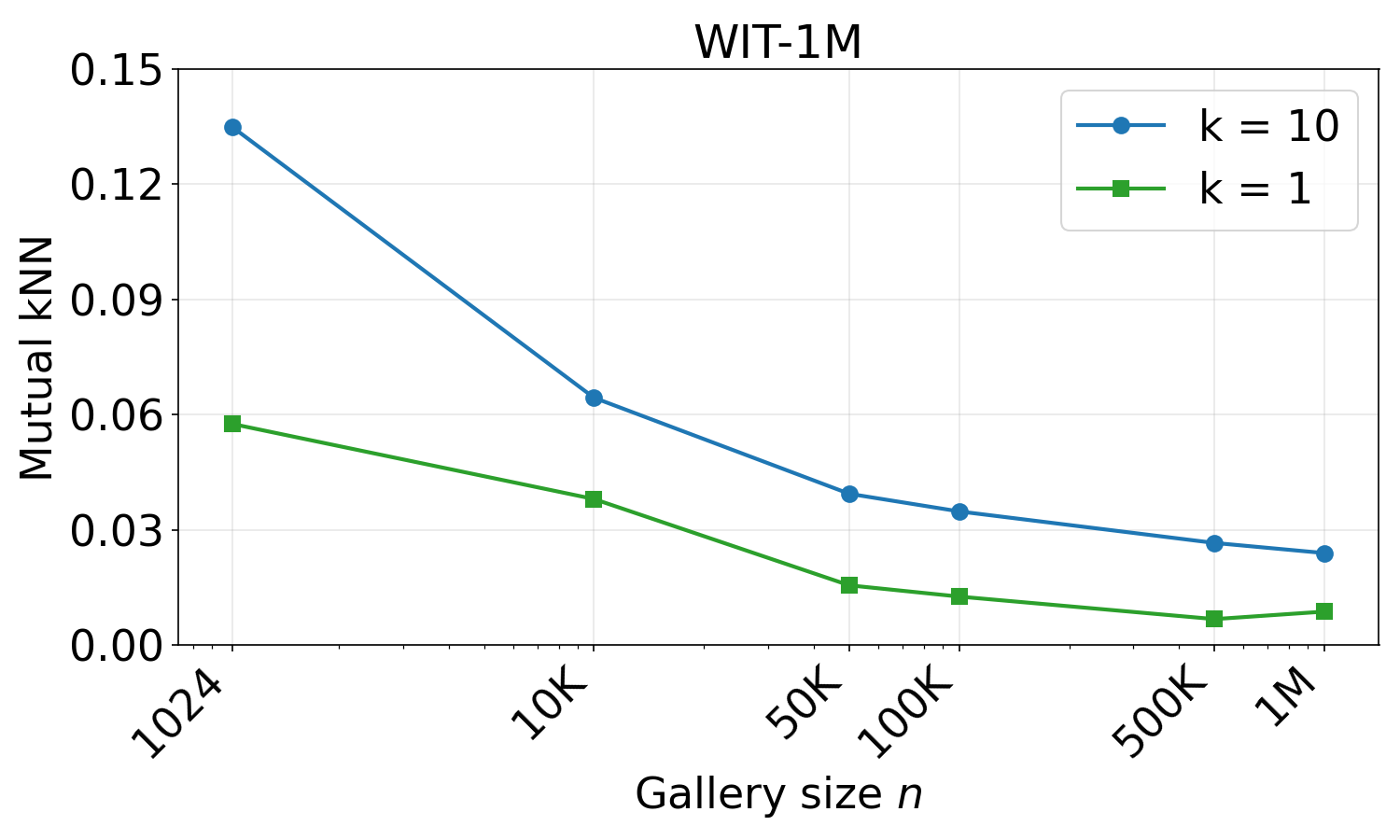
Scaling the dataset to 1M (WIT) shows a large drop in mutual k-NN alignment for both k=1 and k=10.
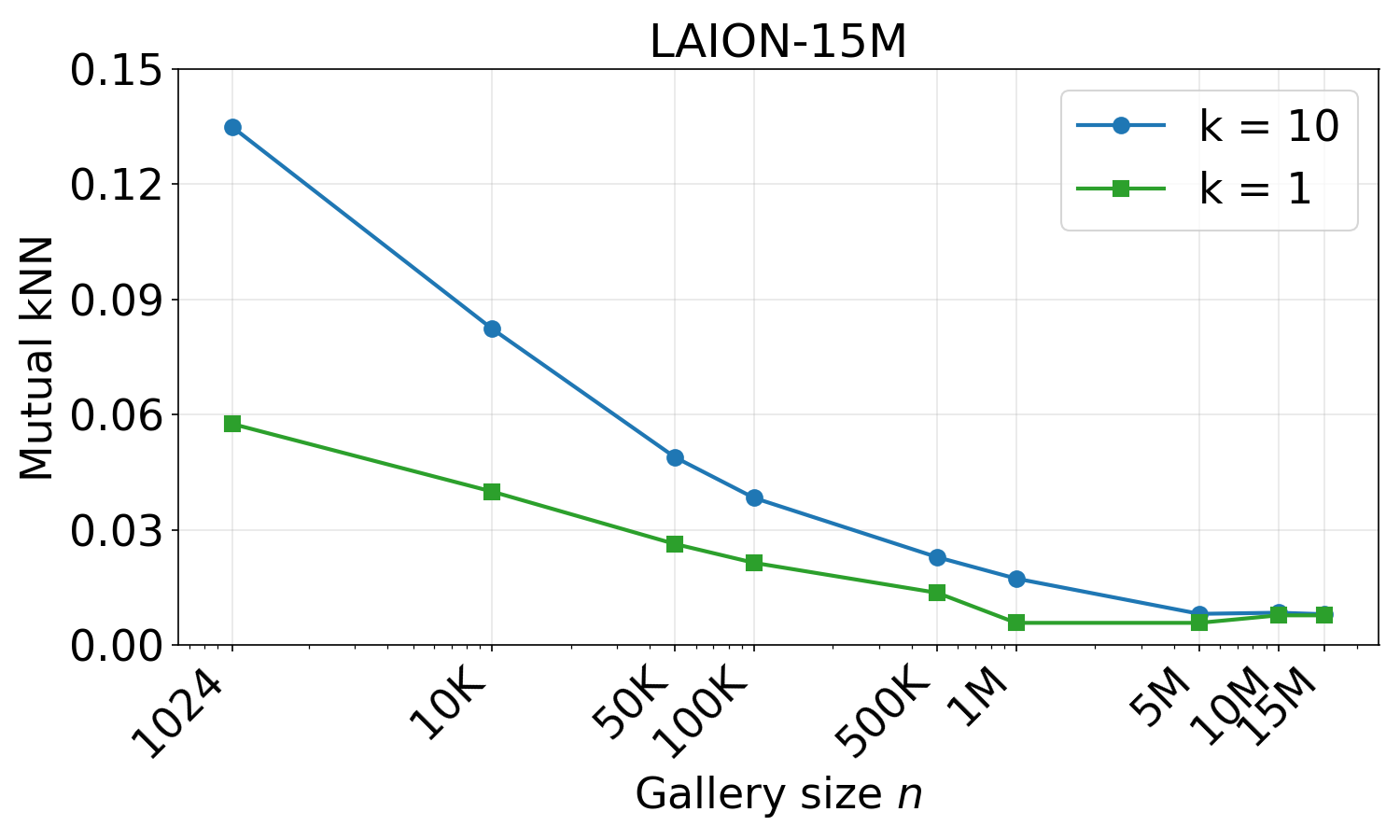
We see a similar alignment degradation on LAION-15M when scaling to 15M samples.
The original experiments used one-to-one image-text pairings. But real data is many-to-many: a single image can be described in countless ways, and a single caption can match many different images. When we progressively add more captions per image or more images per caption, mutual k-NN alignment drops consistently.
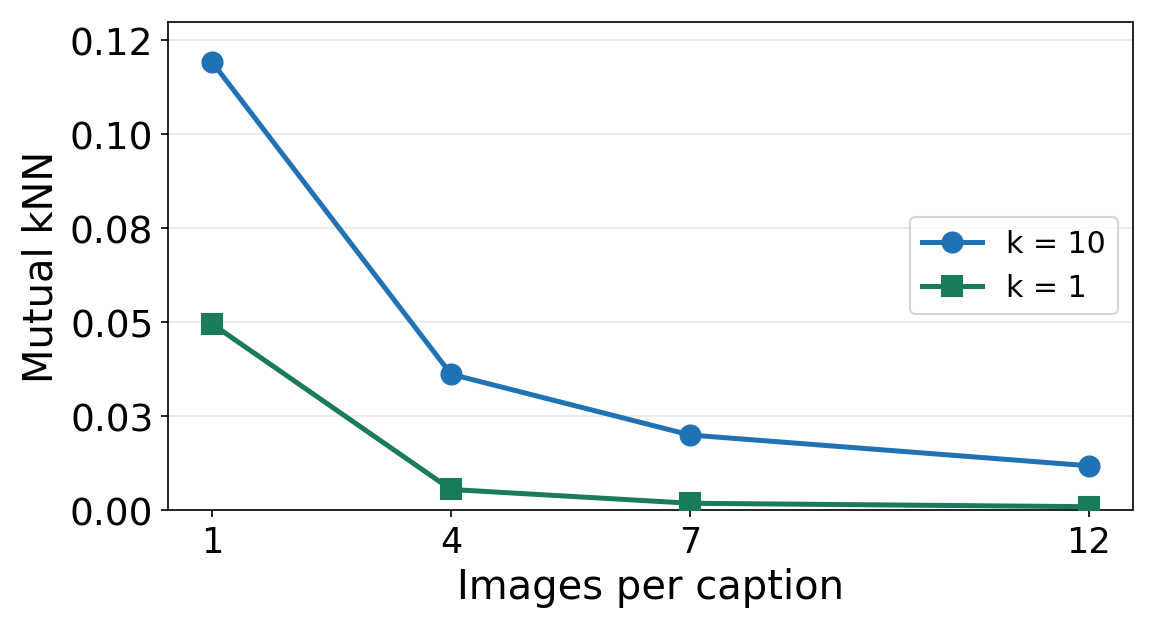
Adding more images per caption using CycleReward data. Mutual k-NN alignment decreases consistently for both k=1 and k=10.
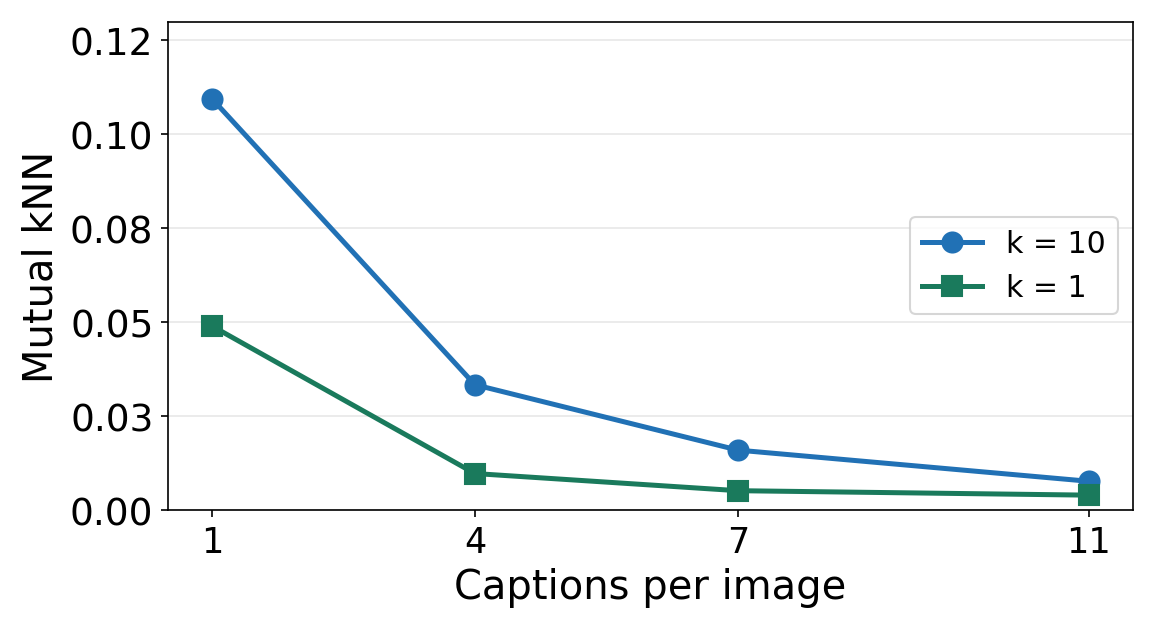
Adding more captions per image gives the same pattern. Alignment drops as the one-to-one setting is relaxed.
Both models might retrieve a "stone wall", but the vision model finds one with a similar texture, while the language model finds interlocking concrete blocks. Same category, different items.
Each dot represents an image-text pair, shown in both the image embedding space (left, DINOv2) and text embedding space (right, OpenLlama3b). As the number of images per class grows, both models find closer neighbors in their own space, but they no longer agree on the same item. Hover over a dot to see its caption.
To quantify this phenomenon, we turn to ImageNet, where every image has a class label. We decompose the mutual k-NN metric into three questions:
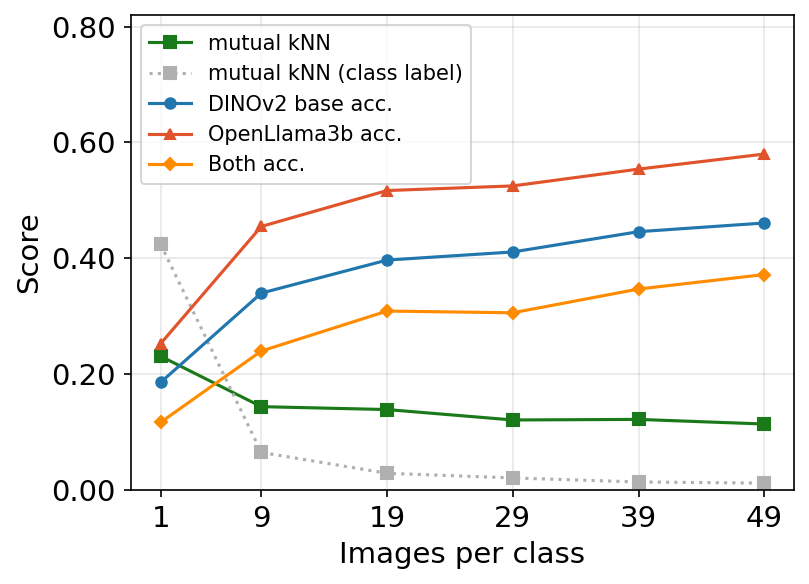
Per-modality retrieval accuracy and cross-modal mutual k-NN alignment (k=1) as images per class increase. As the dataset densifies, both DINOv2 and OpenLlama3b individually retrieve correct-class neighbors at rising rates, but cross-modal alignment remains flat: the models agree on the category but not on the specific instance.
The limited alignment we do observe is just coarse categorical agreement. Both models know what a stone wall is, but they have fundamentally different ideas about which walls are most similar to each other.
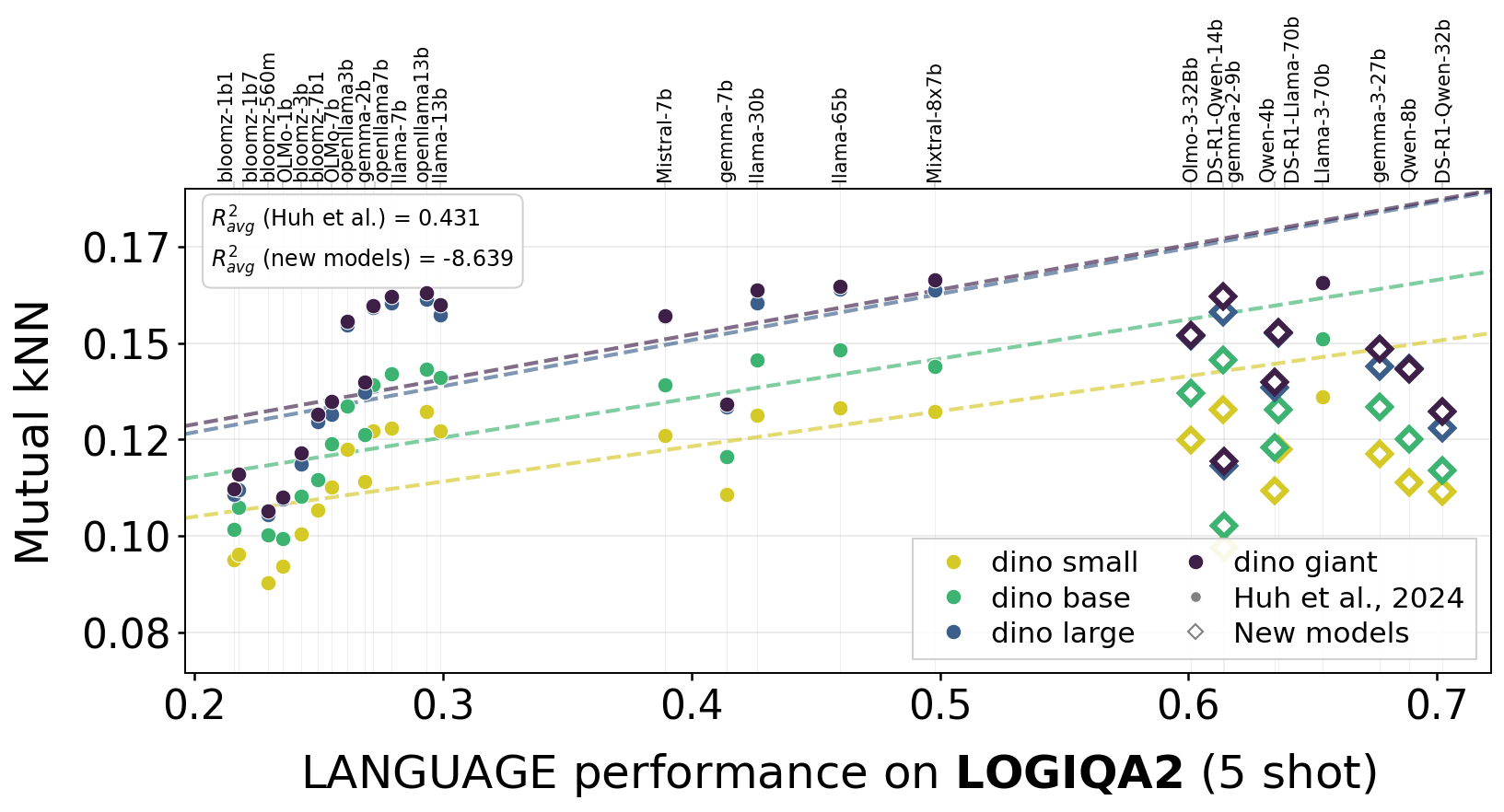
One argument for convergence was that stronger language models align better with vision models. We tested this across 55 language models and multiple benchmarks.
The trend (shown as dashed lines) from the models used in the original Platonic Representation Hypothesis experiments does not seem to hold for recent models (diamonds that are off the lines). Indeed, newer models appear to be specializing in their own modality.
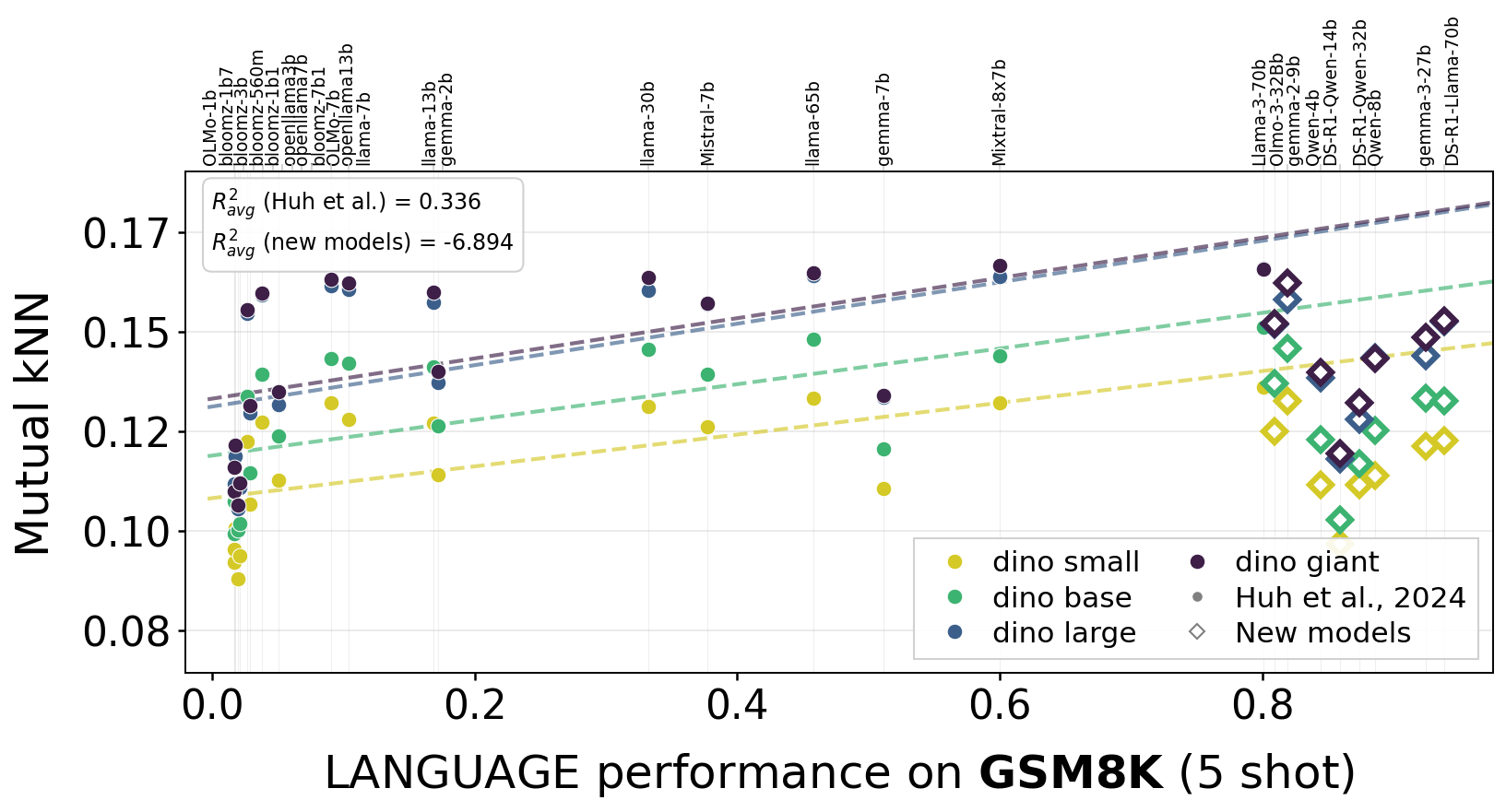
GSM8K
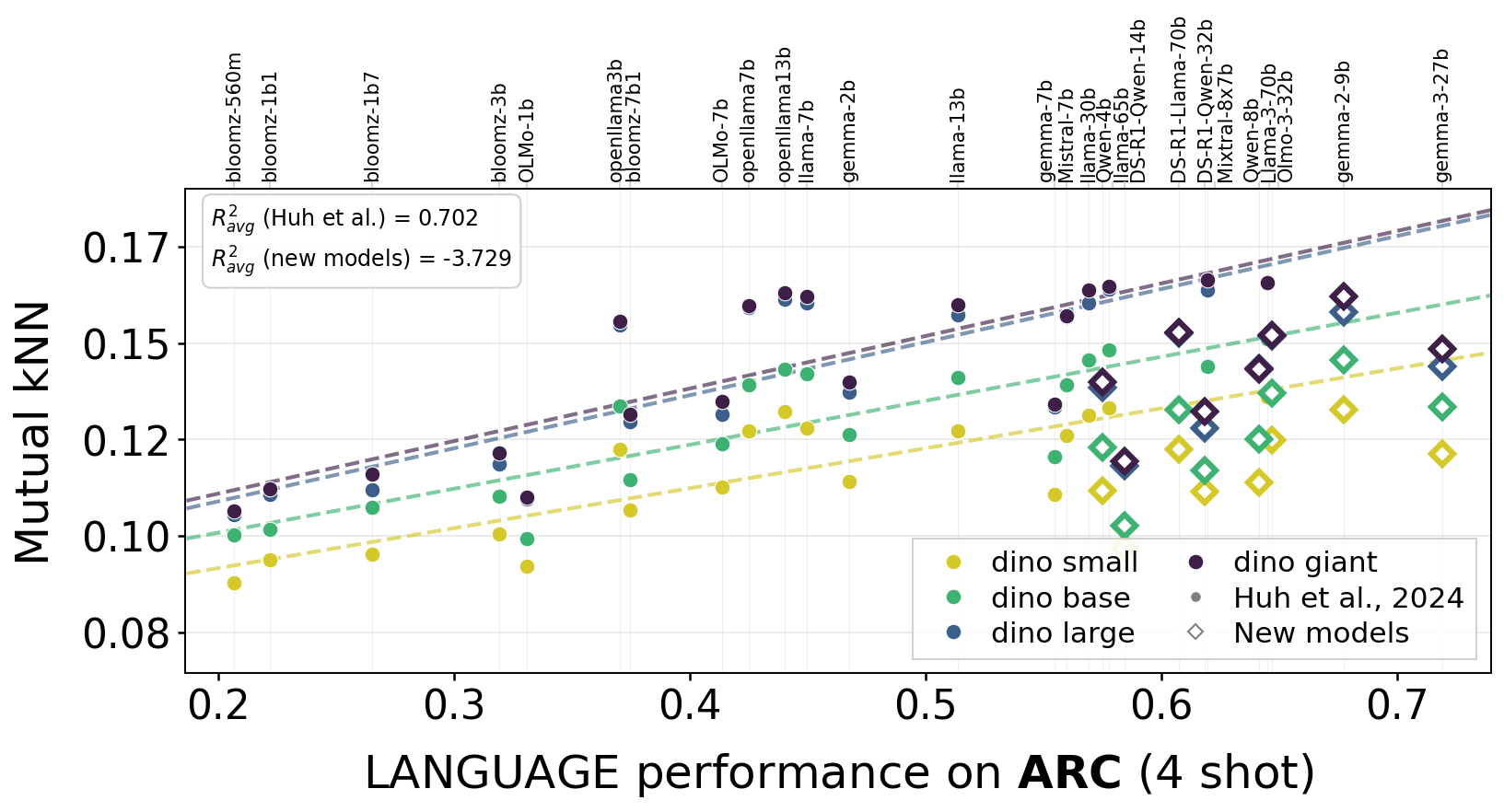
ARC
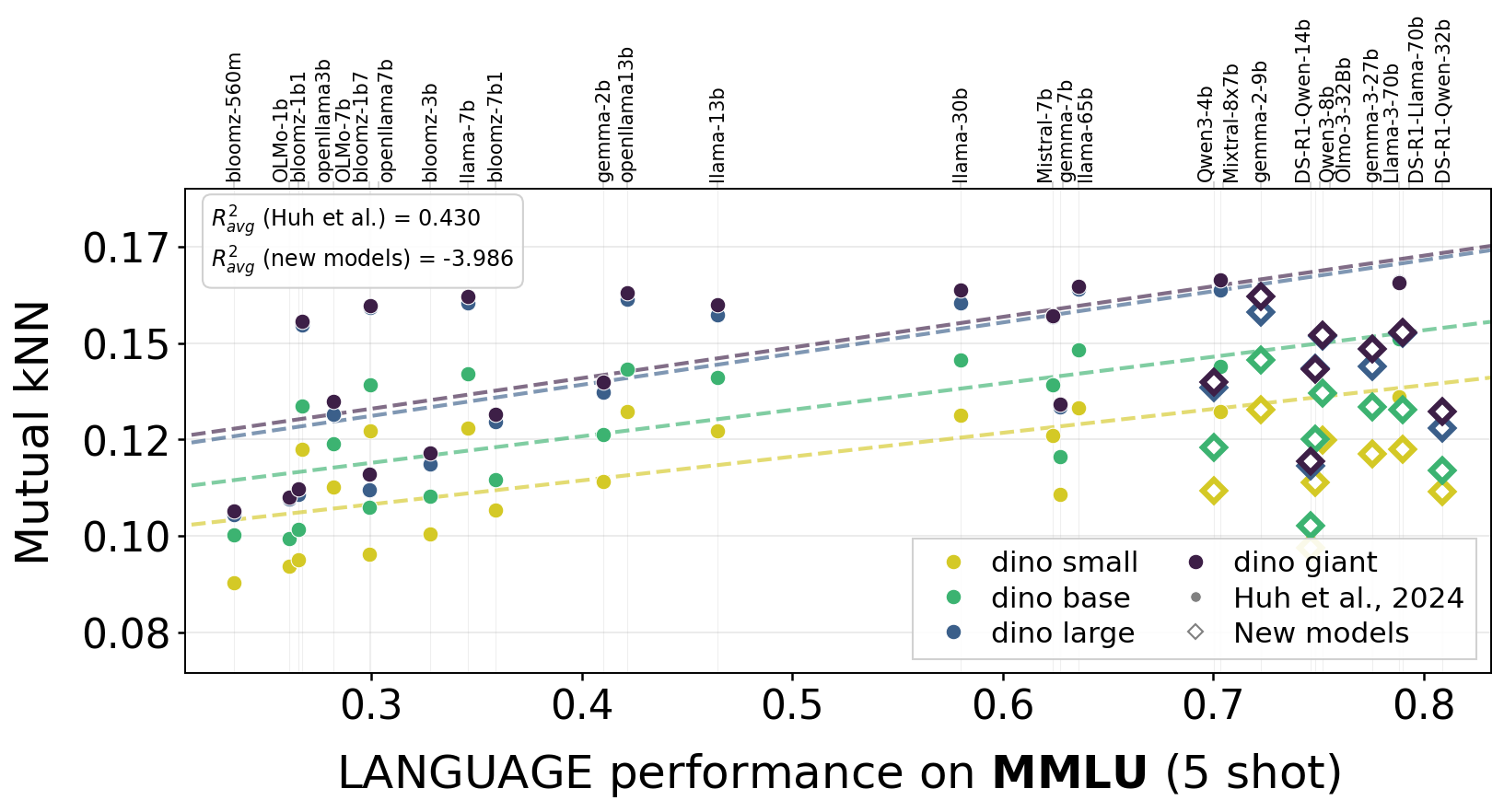
MMLU
LogiQA2
Alignment vs. language model capability across four benchmarks. Dashed lines show the original trend from the Platonic Representation Hypothesis; diamonds represent recent models that fall off the predicted scaling curve. Stronger LLMs don't appear to align better with vision.
Nearly a century ago, biologist Jakob von Uexküll argued that every organism inhabits its own perceptual environment, or Umwelt: a tick lives in a world of thermal gradients, a bat in a world of echoes. The different Umwelten might have only little overlap with each other.2 The same, we believe, might hold for our models: each constructs its own representational structure, determined by its modality and training data, rather than converging toward a shared model of reality. Though it is still early days, we suspect future evidence will favor von Uexküll over Plato.
Others have also questioned the hypothesis:
Please get in touch with us if we have left your paper off this list.
Further reading:
@article{koepke2026cave,
title = {Back into Plato's Cave: Examining the Evidence for Cross-modal Representational Convergence},
author = {Koepke, A. Sophia and Zverev, Daniil and Ginosar, Shiry and Efros, Alexei A.},
journal = {arXiv preprint arXiv:2604.18572},
year = {2026}
}🙏 This work was in part supported by the BMFTR (FKZ: 16IS24060), the DFG (SFB 1233, project number: 276693517), NSF IIS-2403305, and ONR MURI. This research utilized compute resources at the Tübingen Machine Learning Cloud. The authors thank all Efros group members for valuable discussions that shaped this work, and particularly Tyler Bonnen and Amil Dravid for proofreading the draft. Lastly, we thank Phillip Isola for feedback and for sparking this conversation by inviting us out of the cave, which ended up motivating us to go back in to examine the shadows in a new light.
