|
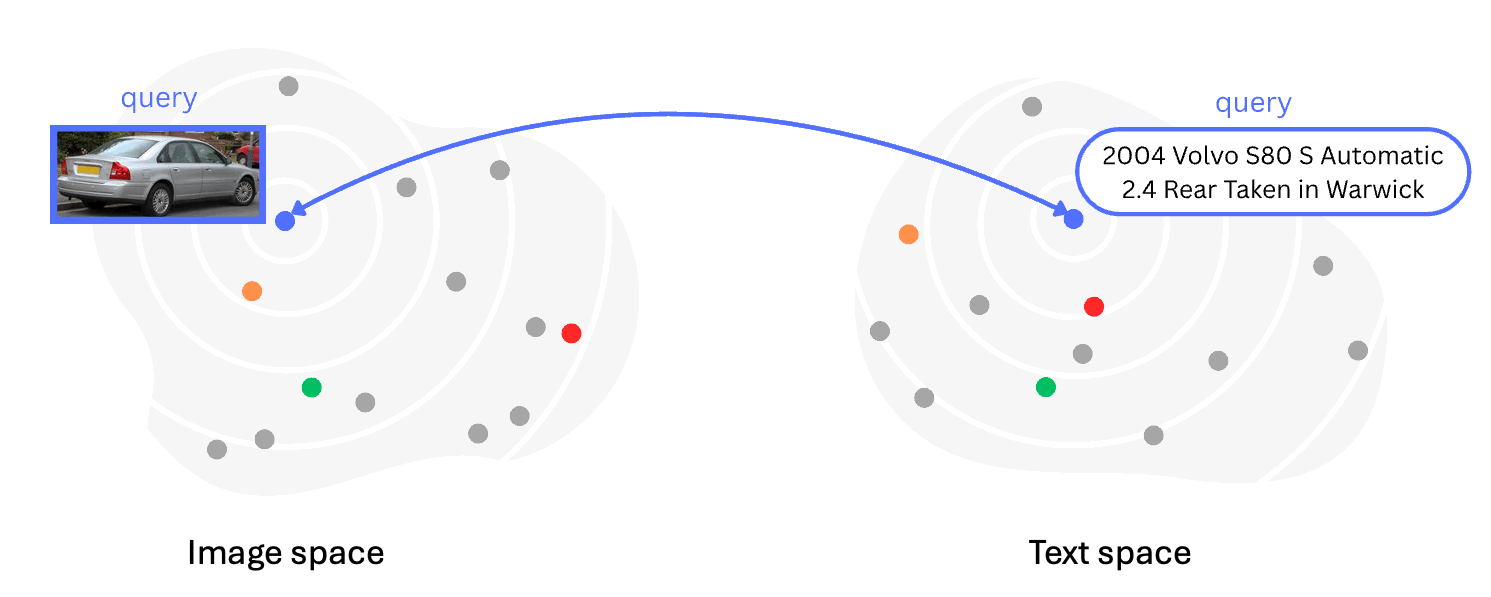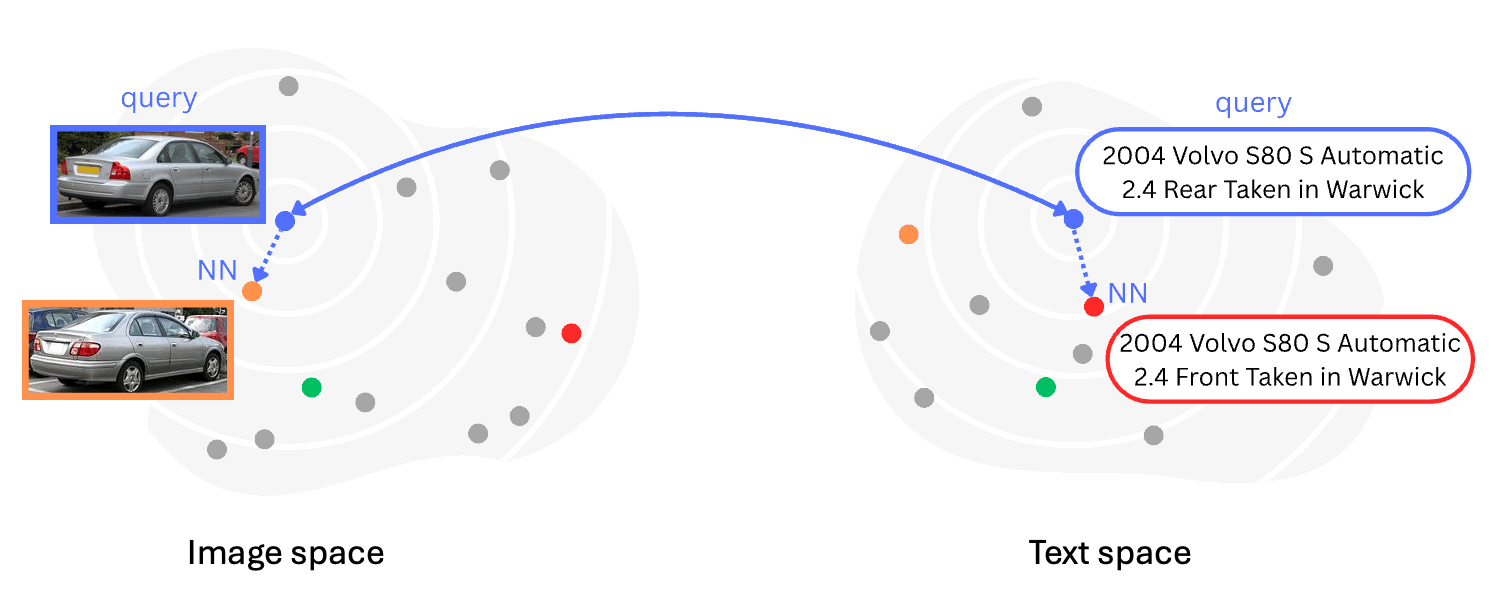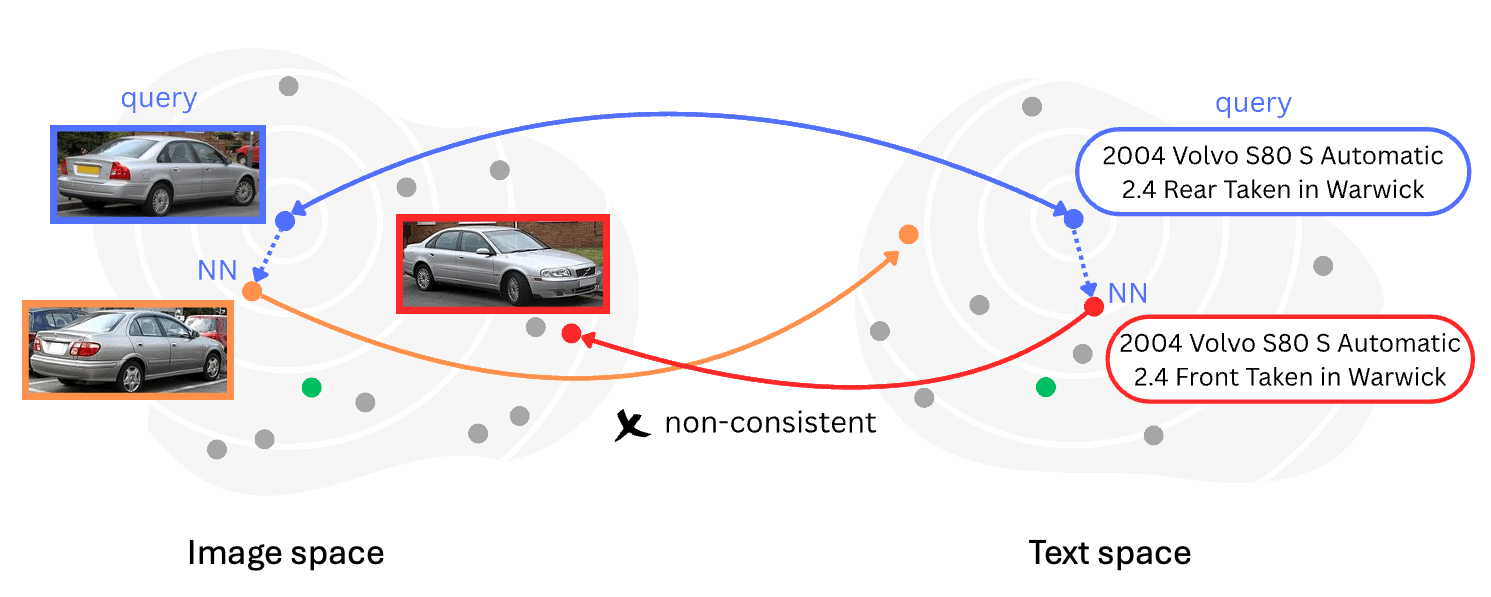
Back into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
A. Sophia Koepke,
Daniil Zverev,
Shiry Ginosar,
Alexei A. Efros
arXiv preprint, 2026
paper
/
project page
/
code
|
|
|

|
It's never too late: Noise optimization for collapse recovery in trained diffusion models
Anne Harrington*,
A. Sophia Koepke*,
Shyamgopal Karthik,
Trevor Darrell,
Alexei A. Efros
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
paper
/
project page
/
code
|
|
|

|
VGGSounder: Audio-visual evaluations for foundation models
Daniil Zverev*,
Thaddäus Wiedemer*,
Ameya Prabhu,
Matthias Bethge,
Wieland Brendel,
A. Sophia Koepke
IEEE/CVF International Conference on Computer Vision (ICCV), 2025
paper
/
project page
/
code
VGGSounder v1.0 received an additional round of manual verification (released on June 30, 2026). Per-modality multi-class annotations for the audio-visual VGGSound data.
|
|
|

|
On the dangers of bootstrapping generation for continual learning and beyond
Daniil Zverev,
A. Sophia Koepke,
João F. Henriques
DAGM German Conference on Pattern Recognition (GCPR), 2025
paper
|
|
|
|
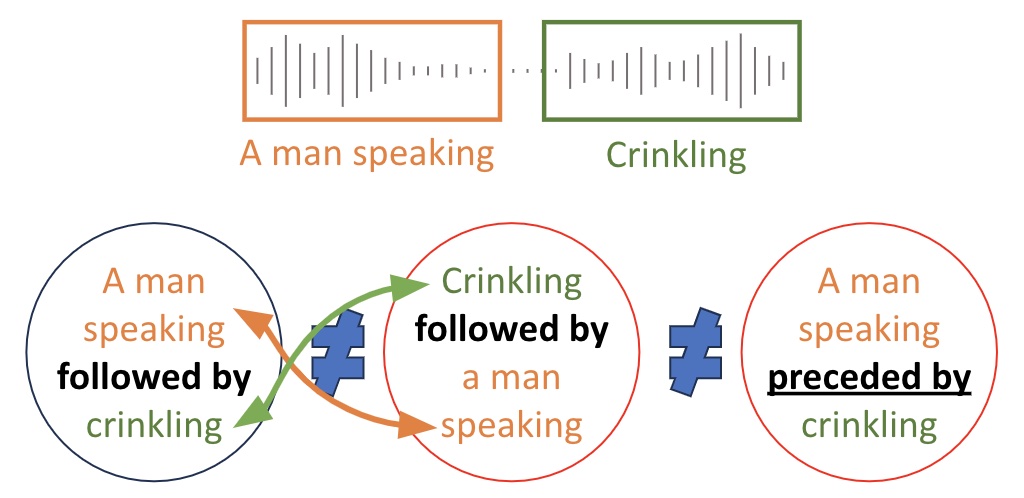
Dissecting temporal understanding in text-to-audio retrieval
Andreea-Maria Oncescu,
João F. Henriques,
A. Sophia Koepke
ACM Multimedia (ACMMM), 2024
paper
/
project page
/
code
|
|
|
|
Fantastic gains and where to find them: On the existence and prospect of general knowledge transfer
between any pretrained model
Karsten Roth*,
Lukas Thede*, A. Sophia Koepke,
Oriol Vinyals,
Olivier J. Hénaff,
Zeynep Akata
International Conference on Learning Representations (ICLR), 2024
paper
/
code
/
openreview
Spotlight.
|
|
|
|
Audio-visual generalized zero-shot learning using pre-trained large multi-modal models
David Kurzendörfer,
Otniel-Bogdan Mercea,
A. Sophia Koepke,
Zeynep Akata
Workshop on Learning with Limited Labelled Data for Image and Video Understanding at
the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
paper
/
code
|
|
|

|
A sound approach: Using large language models to generate audio descriptions for egocentric text-audio
retrieval
Andreea-Maria Oncescu,
João F. Henriques,
Andrew Zisserman,
Samuel Albanie,
A. Sophia Koepke
The International Conference on Acoustics, Speech, & Signal Processing (ICASSP), 2024
paper
/
project page
/
code
|
|
|
|
Addressing caveats of neural persistence with deep graph persistence
Leander Girrbach,
Anders Christensen,
Ole Winther,
Zeynep Akata,
A. Sophia Koepke
Transactions on Machine Learning Research (TMLR), 2023
paper
/
code
/
openreview
/
video
A part of this was also presented at the TAG-ML Workshop at ICML 2023.
|
|
|

|
Zero-shot audio captioning with audio-language model guidance and audio context keywords
Leonard Salewski, Stefan Fauth,
A. Sophia Koepke,
Zeynep Akata
NeurIPS Workshop on Machine Learning for Audio, 2023
paper
/
code
|
|
|
|
Video-adverb retrieval with compositional adverb-action embeddings
Thomas Hummel,
Otniel-Bogdan Mercea,
A. Sophia Koepke,
Zeynep Akata
British Machine Vision Conference (BMVC), 2023
paper
/
project page
/
code
Oral presentation.
|
|
|
|
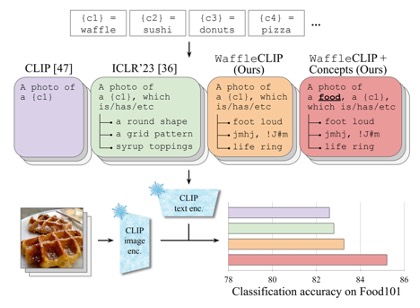
Waffling around for performance: Visual classification with random words and broad concepts
Karsten Roth,
Jae Myung Kim, A. Sophia Koepke,
Oriol Vinyals,
Cordelia Schmid,
Zeynep Akata
IEEE/CVF International Conference on Computer Vision (ICCV), 2023
paper
/
code
|
|
|
|
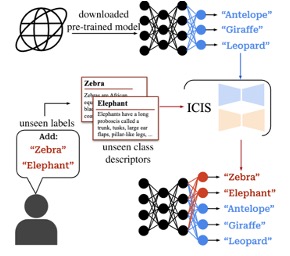
Image-free classifier injection for zero-shot classification
Anders Christensen,
Massimiliano Mancini,
A. Sophia Koepke, Ole Winther,
Zeynep Akata
IEEE/CVF International Conference on Computer Vision (ICCV), 2023
paper
/
code
|
|
|
|
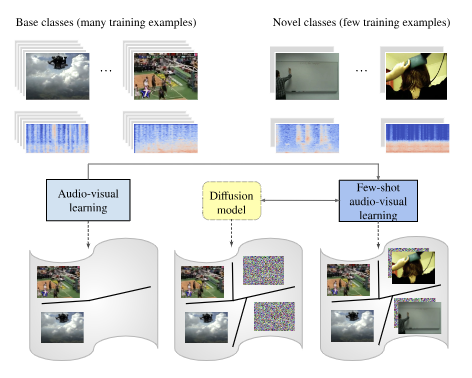
Text-to-feature diffusion for audio-visual few-shot learning
Otniel-Bogdan Mercea,
Thomas Hummel,
A. Sophia Koepke,
Zeynep Akata
DAGM German Conference on Pattern Recognition (GCPR), 2023
paper
/
code
|
|
|
|
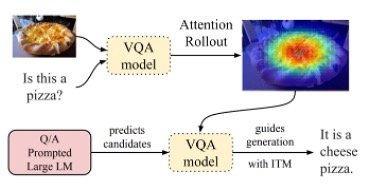
Zero-shot translation of attention patterns in VQA models to natural language
Leonard Salewski,
A. Sophia Koepke,
Hendrik Lensch,
Zeynep Akata
DAGM German Conference on Pattern Recognition (GCPR), 2023
paper
/
code
|
|
|
|
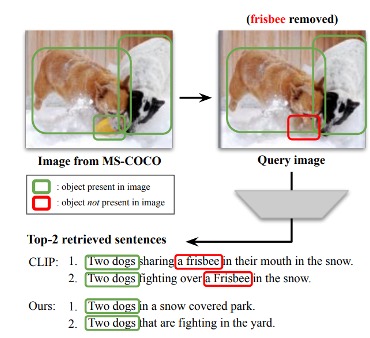
Exposing and mitigating spurious correlations for cross-modal retrieval
Jae Myung Kim, A. Sophia Koepke,
Cordelia Schmid,
Zeynep Akata
Multimodal Learning and Applications Workshop at the IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPRW), 2023
paper
/
code
|
|
|
|
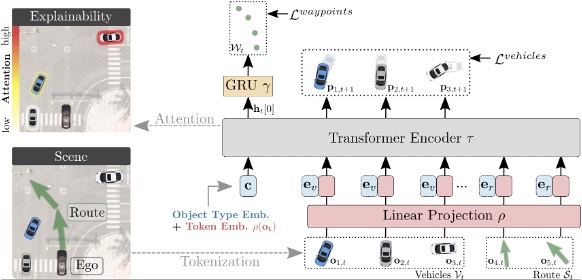
PlanT: Explainable planning transformers via object-level representations
Katrin Renz,
Kashyap Chitta,
Otniel-Bogdan Mercea,
A. Sophia Koepke, Zeynep Akata,
Andreas Geiger
Conference on Robot Learning (CoRL), 2022
paper
/
project page
/
code
|
|
|
|
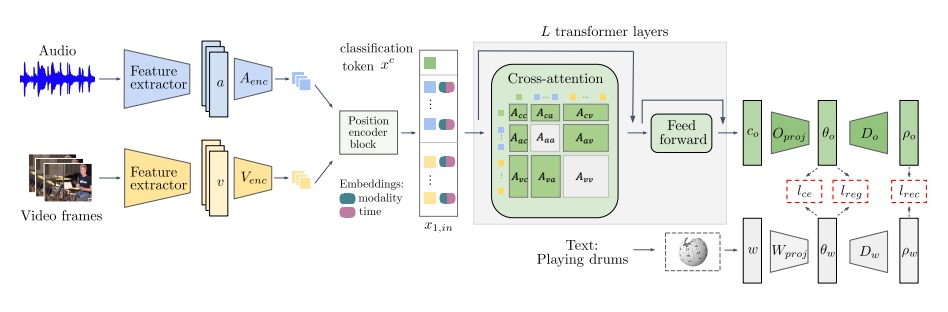
Temporal and cross-modal attention for audio-visual zero-shot learning
Otniel-Bogdan Mercea*,
Thomas Hummel*,
A. Sophia Koepke,
Zeynep Akata
European Conference on Computer Vision (ECCV), 2022
paper
/
code
|
|
|
|
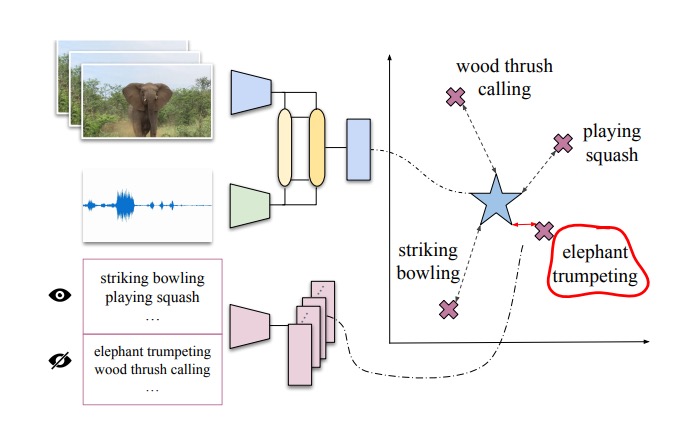
Audio-visual generalised zero-shot learning with cross-modal attention and language
Otniel-Bogdan Mercea, Lukas Riesch,
A. Sophia Koepke,
Zeynep Akata
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
paper
/
code
|
|
|
|
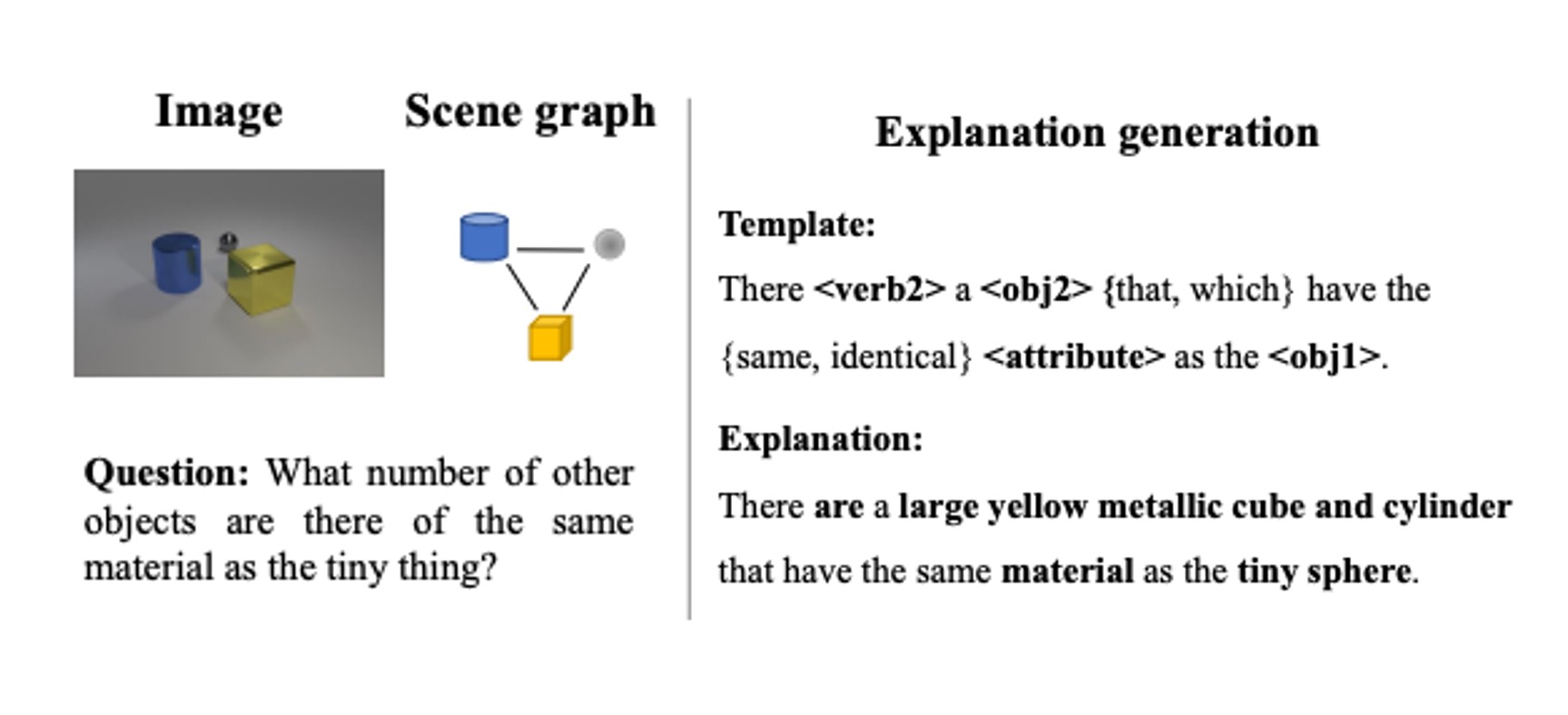
CLEVR-X: A visual reasoning dataset for natural language explanations
Leonard Salewski,
A. Sophia Koepke,
Hendrik Lensch,
Zeynep Akata
Springer Lecture Notes on Artificial Intelligence, 2022
paper
/
project page
/
code
This was also presented at the CVPR 2022 Workshop on Explainable AI for Computer Vision (XAI4CV).
|
|
|
|
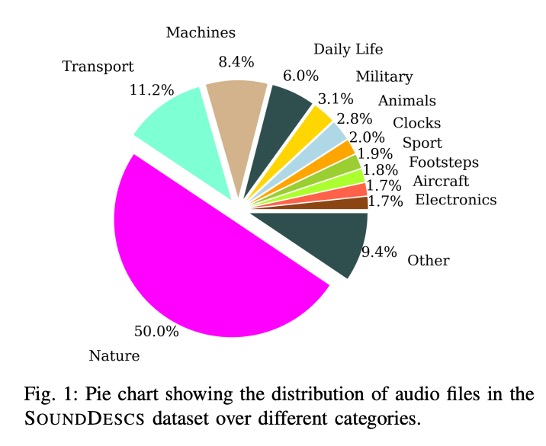
Audio retrieval with natural language queries: A benchmark study
A. Sophia Koepke*,
Andreea-Maria Oncescu*,
João F. Henriques,
Zeynep Akata,
Samuel Albanie
Transactions on Multimedia, 2022
paper
/
project page
/
code
Extension of the INTERSPEECH paper with a new dataset and new results.
|
|
|

|
Audio retrieval with natural language queries
Andreea-Maria Oncescu*,
A. Sophia Koepke*, João F. Henriques,
Zeynep Akata,
Samuel Albanie
INTERSPEECH, 2021
paper
/
project page
/
code
Shortlisted for best student paper award.
|
|
|
|
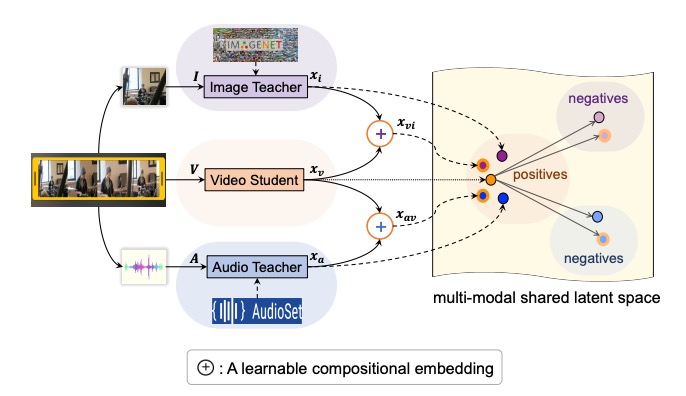
Distilling audio-visual knowledge by compositional contrastive learning
Yanbei Chen,
Yongqin Xian, A. Sophia Koepke,
Ying Shan,
Zeynep Akata
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
paper
/
code
|
|
|
|
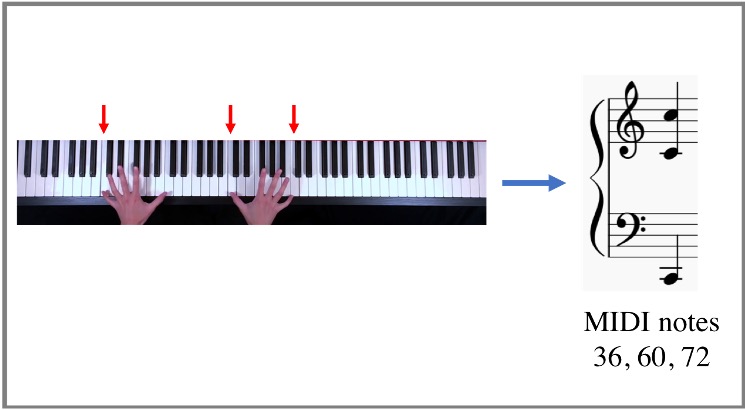
Sight to sound: An end-to-end approach for visual piano transcription
A. Sophia Koepke, Olivia Wiles,
Yael Moses,
Andrew Zisserman
The International Conference on Acoustics, Speech, & Signal Processing (ICASSP), 2020
paper
/
project page
Oral presentation.
|
|
|
|
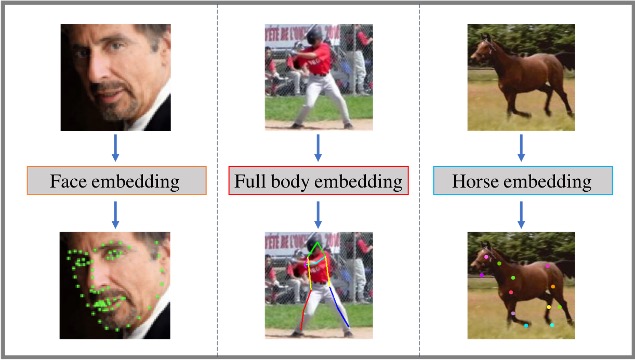
Self-supervised learning of class embeddings from video
Olivia Wiles, A. Sophia Koepke,
Andrew Zisserman
Compact and Efficient Feature Representation and Learning in Computer Vision Workshop at the IEEE/CVF
International Conference on Computer Vision (ICCV Workshop), 2019
paper
|
|
|
|
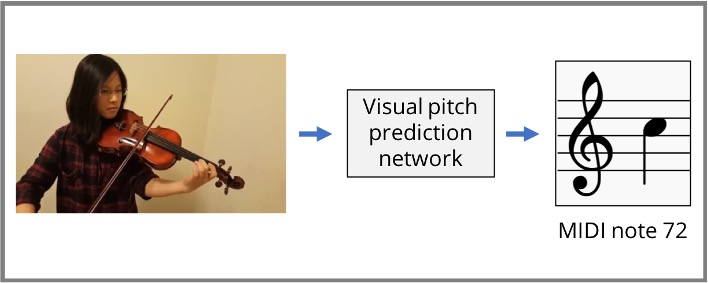
Visual pitch estimation
A. Sophia Koepke, Olivia Wiles,
Andrew Zisserman
Sound and Music Computation Conference (SMC), 2019
paper
/
project page
|
|
|
|
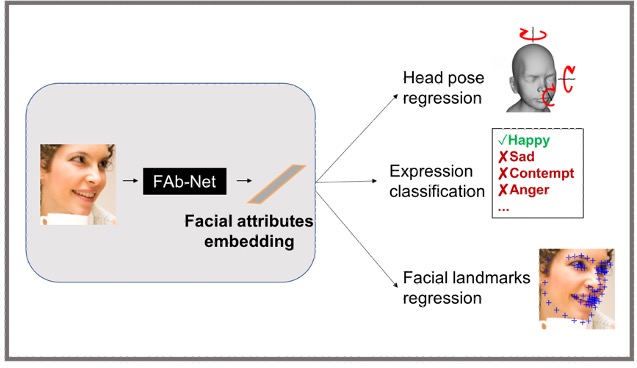
Self-supervised learning of a facial attribute embedding from video
Olivia Wiles*, A. Sophia Koepke*,
Andrew Zisserman
British Machine Vision Conference (BMVC), 2018
paper
/
supplementary material
/
project page
/
code
Oral presentation.
|
|
|

|
X2Face: A network for controlling face generation by using images, audio, and pose codes
Olivia Wiles*, A. Sophia Koepke*,
Andrew Zisserman
European Conference on Computer Vision (ECCV), 2018
paper
/
project page
/
code
|
|
| * denotes equal contribution |